Simple diagrams of convoluted neural networks
15 Sept 2018 | by Piotr Migdał
A good diagram is worth a thousand equations — let’s create more of these!
Neural networks are complicated, multidimensional, nonlinear array operations. How can we present a deep learning model architecture in a way that shows key features, while avoiding being too complex or repetitive? How can we present them in a way that is clear, didactic and insightful? (Bonus points if it is beautiful as well!). Right now, there is no standard for plots — neither for research nor didactic projects. Let me take you through an overview of tools and techniques for visualizing whole networks and particular blocks!
The baseline
AlexNet was a breakthrough architecture, setting convolutional networks (CNNs) as the leading machine learning algorithm for large image classification. The paper introducing AlexNet presents an excellent diagram — but something is missing…
 (2012), the original crop](/_astro/alexnet_original_cropped.CI1Q9x-z_1aFVxa.webp)
It does not require an eagle eye to spot it — the top part is accidentally cropped. And so it runs through all subsequent slide decks, references, etc. In my opinion, it is a symptom that, in deep learning research, visualization is a mere afterthought (with a few notable exceptions, including the Distill journal).
One may argue that developing new algorithms and tuning hyperparameters are Real Science/Engineering™, while the visual presentation is the domain of art and has no value. I couldn’t disagree more!
Sure, for computers running a program it does not matter if your code is without indentations and has obscurely named variables. But for people — it does. Academic papers are not a means of discovery — they are a means of communication.
Take another complex idea — quantum field theory. If you want to show the electron-positron annihilation process, creating a muon-antimuon pair, here’s theFeynman diagram (of the first-order term):
](/_astro/feynman_diagram.CO15Gad__PkhLx.webp)
Cute, isn’t it? But it is not an artistic impression. It is a graphical representation of the scattering amplitude, with each line being a propagator and each vertex — a point interaction. It directly translates to:
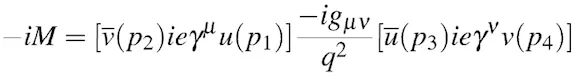
I may be biased towards “making things simpler” as I did with complex tensor operations in JavaScript, and visualized their results before it was cool (for Quantum Game with Photons). Yet, there is more to the Feynman diagrams analogy than using visual representations for formulae. In both quantum mechanics and deep learning, we do a lot of linear algebra with tensor structures. In fact, one may even use the Einstein summation convention in PyTorch.
Explaining neural network layers
Before we jump into network architectures, let’s focus on their building blocks — layers. For example, a Long Short-Term Memory (LSTM) unit can be described with the following equation:
Sure, it’s reasonably easy to parse these equations. At least — if you are already familiar with matrix multiplication conventions. But it is a very different thing to parse something, and to understand it. When I saw LSTM equations for the first time I could parse it, yet I had no idea what was going on.
By “understanding” I don’t mean some spiritual sense of enlightenment — it may be as pleasing and intoxicating as misleading. Instead, I mean building a mental model we are able to work with (to explain, simplify, modify, predict what-if scenarios, etc). Often a graphical form may be cleaner than a verbal one:
 (2015)](/_astro/lstm_visualization_olah.BqLN8UhZ_Z20e5EG.webp)
Understanding LSTM Networks is a wonderful blog post about LSTM cells that explains depicted operations in a step-by-step manner. It gave me a big “Eureka!” moment, turning a seemingly random set of multiplications into a reasonable approach to writing (and reading!) data.
And here is an even more explicit diagram of LSTM below:
 (2018)](/_astro/lstm_detailed_benderski.D8AbWyuo_1JNfly.webp)
In my opinion:
A good diagram is worth a thousand equations.
It works for almost any other blocks. We can visualize concepts such as dropout (i.e. switching-off neurons, and rendering their connections irrelevant):
 (2014)](/_astro/dropout_visualization.DoU84nQ4_1vvXPN.webp)
While I am not a big fan of drawing data flows upside-down, this figure is very clear.
Graphical representations are useful for explaining compound blocks, composed of smaller ones (e.g. a few subsequent convolutions). Take a look at this Inception module diagram:
 (2015)](/_astro/inception_module.aUdPxjDp_lUGwq.webp)
Each visualization is different — not only in the terms of its style but what does it put an emphasis on, and what does it abstract away. What’s important? The number of layers, connections between them, convolution kernel size or activation function? Well, it depends. Abstraction means “the process of considering something independently of its associations or attributes”. The challenge is to decide what is important for a given communication, and what should be hidden.
For example, in this Batch Normalization diagram, the emphasis is on the backward pass:
 (2016)](/_astro/batch_normalization_backward.DrvoIxoB_L6XNp.webp)
Data viz vs data art
You may get the impression that I argue for making deep learning papers more visually appealing. Well, it wouldn’t hurt to make charts nicer. When I work with data exploration, I often pick nicer color schemes just to make a more pleasant experience. My main point is to turn visualizations into a more effective means of communication.
So, does nicer mean better? Not necessarily. The Line between Data Vis and Data Art by Lisa Charlotte Rost, which I found very insightful, explains the distinction.
 (2015)](/_astro/data_vis_vs_data_art.TWMlo6U8_1PLoV1.webp)
For example, look this stunning picture below:
 (2016)](/_astro/graphcore_ai_brain.noFuHVUl_Z1hUocL.webp)
Beautiful, isn’t it? To me, it looks alive — like a cell, with its organelle. …but hey — can we deduce anything from it? Would you even guess it’s the same AlexNet?
In another example, an animated multi-layer perceptron is focused on its aesthetic, rather than explanatory, value:
 (2016)](/_astro/neural_network_animation.D794K_4Z_Z297xfs.webp)
To make it clear: data art has value on its own, as long as we don’t confuse artistic value with educational value. If you like going this route, I encourage you to use 3D animations of impulses such as these sparks or that colorful brain — for an actual ConvNet.
Sometimes the trade-off is less clear. This one, is it data viz or data art?
 (2014)](/_astro/googlenet_visualization.BvlUKYZ8_1dPq8y.webp)
I guess you said: “data vis, obviously”. In this case — we are in disagreement. While there is a nice color scheme, and the repetition of similar structures is visually pleasing, it is hard to implement this network solely based on this drawing. Sure, you get the gist of the architecture — i.e. the number of layers, and on the structure of blocks, but it’s not enough to reimplement the network (at least, not without a magnifying glass).
To make it clear — there is room for data art in publications. For example, in a network for detecting skin conditions, we see the diagram of Inception v3 feature-extracting layers. Here it is clear that the authors just use it, and represent it graphically, rather than explain its inner workings:
 (2017)](/_astro/inception_skin_cancer.Ff0Jd4al_Z1Jrit2.webp)
And how would you classify this diagram, for exploring visual patterns that activate selected channels?
 (2017), distil.pub](/_astro/feature_visualization.D8J-hE4K_Z2mSDf1.webp)
I would classify the diagram below as a good example of data-viz. A trippy visualization does not make it a piece of data art. In this case, the focus is on network architecture abstraction and presenting relevant data (input images activating a given channel).
Some diagrams abstract a lot of information, giving only a very general idea of what is going on. See the Neural Network Zoo and its prequel:
 (2016), a fragment](/_astro/neural_network_zoo.nhP0Qch7_2033it.webp)
Explanatory architecture diagrams
We saw a few examples of layer diagrams, and pieces of data art related to neural network architectures.
Let’s go to (data) visualizations of neural network architectures. Here is the architecture of VGG16, a standard network for image classification.
](/_astro/vgg16_architecture.BCvgtKpp_1vkP5v.webp)
We see, step-by-step, tensor sizes and operations (marked as colors). It’s not abstract — box sizes are related to tensor shapes. Bear in mind that the thickness related to the number of channels is not to scale (well, we have 3 to 4096).
A similar approach is to show values for each channel, as in this DeepFace work:
 (2014)](/_astro/deepface_visualization.C01o6XiA_Z1imBfl.webp)
Such diagrams are not restricted to computer vision. Let’s see one for turning text into… colors:
 (2018)](/_astro/text_to_colors_network.DJtj9WDU_1Rvt3g.webp)
Such diagrams might be useful if the goal is to show the network architecture and at the same time — give some hints on its inner workings. They seem to be especially useful for tutorials, e.g. the seminal The Unreasonable Effectiveness of Recurrent Neural Networks.
Abstract architecture diagrams
However, for larger models, explanatory diagrams may be unnecessarily complex or too specific to show all possible layers within a single diagram style. So, the way to go is to use abstract diagrams. Typically, nodes denote operations, while arrows represent the tensor flow. For example, let’s look at this VGG-19 vs ResNet-34 comparison:
 (2015), cropped](/_astro/resnet_vs_vgg.D9Gtenl2_2kR4qJ.webp)
We can see that there is some redundancy, as some units get reused or repeated. Since diagrams can be long (there is a reason why I cropped the one above!), it is beneficial to spot the patterns and consolidate them. Such a hierarchy makes it simpler both to understand concepts and present them visually (unless we just want to create data-artsy diagrams of GoogLeNet).
For example, let’s look at this one, of Inception-ResNet-v1:
 (2016), combined two figures](/_astro/inception_resnet_v1.ktH89bWt_2n7Iwn.webp)
I adore its composition — we see what’s going on, and which blocks are being repeated.
Another diagram that made a concept super clear to me was one for image segmentation, U-Net:
 (2015)](/_astro/unet_architecture.CxOu6gJ0_Z1aGUHv.webp)
Take note that this time nodes denote tensors, whereas arrows represent operations. I find this diagram very clear — we see tensor shapes, convolutions, and pooling operations. Since the original U-Net architecture is not too complex, we can do without looking at its hierarchical structure.
The task of creating clear diagrams get slightly more complicated when we want to use more complex building blocks. If we want to reproduce the network, we need to know its details:
- Number of channels
- Convolutions per MaxPool
- Number of MaxPools
- Batch normalization or dropout
- Activation functions (ReLU? before or after Batch Norm?)
As a great example of condensing this level of detail into a diagram, see the diagram below:
 (2017)](/_astro/deep_learning_satellite_imagery.3RQgWuLZ_1sMDig.webp)
While the color choice could have been better, I adore its explicit form. There is a clear indication of the number of channels. Each complex layer is explicitly decomposed into its building blocks, maintaining all details (note 3-level hierarchy).
Another interesting approach to the neural network module hierarchy:
 (2016)](/_astro/adaptnet_architecture.BHcwN30f_Z107hOj.webp)
Automatic tools for neural network architecture visualization
You can draw your network manually. Use Inkscape (as Chris Olah did), TikZ (if you are a fan of LaTeX) or any other tool. The other one is to generate them automatically.
I hope that you are aware that you already interact with one visual representation — code (yes, a text is a visual representation!). For some projects, the code might suffice, especially if you work with a concise framework (such as Keras or PyTorch). For more convoluted (pun totally intended) architectures, diagrams add a lot of explanatory value.
TensorBoard: Graph
TensorBoard is arguably the most popular network visualization tool. A TensorFlow network graph looks like this:
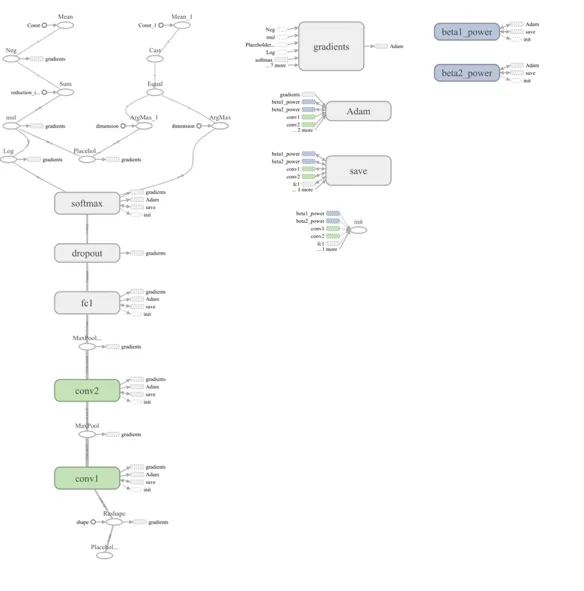
Does it provide a readable summary for a neural network?
In my opinion, it does not.
While this diagram shows the structure of computations, some things are long-winded (e.g. adding bias as a separate operation). Additionally, the most important parts are being masked: the core parameters of operations (e.g. convolution kernel size), and tensor sizes. Though, before going into criticising, I really encourage reading the accompanying paper:
- K. Wongsuphasawat, D. Smilkov et al, Visualizing dataflow graphs of deep learning models in TensorFlow, 2018
This article provides insight into the many challenges of creating network diagrams bottom-up. Since we are allowed to use all TensorFlow operations, including auxiliary ones (such as initialization or logging), it is challenging to make a general, readable graph. If we don’t assume much about what is important to the reader(e.g. that convolution kernel size may vary, but all operations are expected to have a bias), it is hard to make a general tool for turning any TensorFlow computation diagram into a useful (think: publication-ready) diagram.
Keras
Keras is a high-level deep learning framework and therefore has huge potential for beautiful visualizations. (Side note: if you want to use an interactive train graph for Jupyter Notebook, I wrote one: livelossplot.) Yet, in my opinion, its default visualizing option (using GraphViz) is not stellar:
](/_astro/keras_visualization.C58w72Mr_ZppMJK.webp)
I think it hides important details, while provides redundant data (duplicated tensor sizes). Aesthetically, I don’t love it nearly much as Mike Bostock does.
I tried to write another one, keras-sequential-ascii for trainings:
 (2017)](/_astro/keras_sequential_ascii.D2hQApAD_2tQVoM.webp)
This structure works for small-sized sequential network architectures. I’ve found it useful for training and courses, such as Starting deep learning hands-on: image classification on CIFAR-10. But not for anything more advanced (though, I was advised to use branching viz like from git log). And, apparently, I am not the only one who tried ASCII art for neural network viz:
 (2016)](/_astro/keras_ascii_brian_low.DykcOkQc_1aFk2i.webp)
Though, I would say that the most aesthetically pleasing is one found in Keras.js (an ambitious project bringing neural networks to the browser, with GPU support):
 (2018)](/_astro/kerasjs_squeezenet.DW2984Dt_1xjcfe.webp)
This project is no longer in active development, in favor of TensorFlow.js. Yet, as it is open-source and modular (using Vue.js framework), it may work as a starting ground for creating a standalone-viz. Ideally, one working in Jupyter Notebook or separate browser window, much alike displaCy for sentence decomposition.
Moniel
Instead of turning a functional neural network into a graph, we can define an abstract structure. In Moniel by Milan Lajtoš the best part is that we can define a hierarchical structure:
 (2017)](/_astro/moniel_visualization.CVVzgfg8_2gJsbz.webp)
I like this hierarchical-structure approach. Moniel was an ambitious idea to create a specific language (rather than, say, to use YAML). Sadly, the project lies abandoned.
Netscope
I got inspired by Netscope CNN Analyzer by dgschwend (based on a project by ethereon). It is a project with many forks, so by now a different one may be more up-to-date:
(2018)](/_astro/netscope_squeezenet.hOuBRgPF_Z1y6o0k.webp)
It is based on Caffe’s .prototxtformat. I love its color theme, the display of channel sizes and mouseover tooltip for exact parameters. The main problem, though, is the lack of a hierarchical structure. Networks get (too) big very soon.
Netron
Another ambitious project: Netron by Lutz Roeder:
 (2018)](/_astro/netron_visualization.gXIpoDfA_Z25n6uC.webp)
It is a web app, with standalone versions. Ambitiously, it reads various formats
Netron supports ONNX (
.onnx,.pb), Keras (.h5,.keras), CoreML (.mlmodel) and TensorFlow Lite (.tflite). Netron has experimental support for Caffe (.caffemodel), Caffe2 (predict_net.pb), MXNet (.model,-symbol.json), TensorFlow.js (model.json,.pb) and TensorFlow (.pb,.meta).
It sounds awesome! Though, it is a bit more verbose than NetScope (with activation functions) and, most fundamentally, it lacks the hierarchical structure. But for a general visualization, it may be the best starting point.
EDIT: Other tools
A few other tools that may be useful or inspiring:
- NN-SVG: LeNet- and AlexNet-style diagrams
- Visualizing CNN architectures side by side with MXNet
- TensorSpace.js — an in-browser 3D visualizations of channels (stunning but hardly useful)
- HiddenLayer — diagrams with ONNX & Graphviz in Jupyter Notebook for TensorFlow, Keras and PyTorch
- PlotNeuralNet — LaTeX code for drawing convolutional neural networks
And a few threads:
- What tools are good for drawing neural network architecture diagrams? — Quora
- How do you visualize neural network architectures? — Data Science Stack Exchange
Conclusion and call for action
We saw quite a few examples of neural network visualization, shedding light on the following trade-offs:
- data viz vs data art (useful vs beautiful)
- explicit vs implicit (should I show ReLU all the time? But what about tensor dimensions?)
- shallow vs hierarchical
- static (works well in publications) vs interactive (provides more information)
- specific vs general (does it work for a reasonably broad family of neural networks?)
- data flow direction (top to bottom, bottom to top, or left to right; hint: please don’t draw bottom-to-top)
Each of those topics is probably worth a Master’s thesis, and all combined — a PhD (especially with a meticulous study of how people do visualize and what are the abstractions.)
I think there is a big opportunity in creating a standard neural network visualization tool, as common for neural network architectures as matplotlib is for charts. It remains a challenge at the intersection of deep learning and data visualization. The tool should be useful and general enough, to become a standard for:
- tutorials in neural networks
- academic publications
- showing network architecture to collaborators
If we want to make it interactive, JavaScript is a must. Be it D3.js, Vue.js, React or any other tech. That way, it is not only easy to make it interactive, but also system agnostic. Take Bokeh as an example — being useful within a Jupyter Notebook, but also — as a standalone website.
Would you like to start a brand new package? Or contribute to an existing one?
If you find any neural network particularly inspiring, or confusing, share it in the comments! :)
Afterwords
This article is based on my talk “Simple diagrams of convoluted neural networks” (abstract, slides) from PyData Berlin 2018 (BTW: and I invite you to PyData Warsaw, 19–20 Nov 2018). Typically I write on my blog p.migdal.pl. Now I give Medium a try, as it is easier to include images than with Jekyll.
I am grateful to Ilja Sperling for fruitful conversations after the talk and to Rafał Jakubanis and Sarah Martin, CSC for numerous remarks on the draft.