king - man + woman is queen; but why?
6 Jan 2017 | by Piotr Migdał
Intro
word2vec is an algorithm that transforms words into vectors, so that words with similar meanings end up laying close to each other. Moreover, it allows us to use vector arithmetics to work with analogies, for example, the famous king - man + woman = queen.
I will try to explain how it works, with special emphasis on the meaning of vector differences, at the same time omitting as many technicalities as possible.
If you would rather explore than read, here is an interactive exploration by my mentee Julia Bazińska, now a freshman in computer science at the University of Warsaw:
Counts, coincidences and meaning
I love letter co-occurrence in the word co-occurrence.
Sometimes a seemingly naive technique gives powerful results. It turns out that merely looking at word coincidences, while ignoring all grammar and context, can provide us insight into the meaning of a word. Consider this sentence:
A small, fluffy roosety climbed a tree.
What’s a roosety? I would say that something like a squirrel since the two words can be easily interchanged. Such reasoning is called the distributional hypothesis and can be summarized as:
a word is characterized by the company it keeps - John Rupert Firth
If we want to teach it to a computer, the simplest, approximated approach is making it look only at word pairs. Let P(a|b) be the conditional probability that given a word b there is a word a within a short distance (let’s say - being spaced by no more than 2 words). Then we claim that two words a and b are similar if
for every word w. In other words, if we have this equality, no matter if there is a word a or b, all other words occur with the same frequency.
Even simple word counts, compared by source, can give interesting results, e.g. in lyrics of metal songs words (cries, eternity or ashes are popular, while words particularly or approximately are not, well, particularly common), see Heavy Metal and Natural Language Processing. See also Gender Roles with Text Mining and N-grams by Julia Silge.
Looking at co-occurrences can provide much more information. For example, one of my projects, TagOverflow, gives insight into the structure of programming, based only on the usage of tags on Stack Overflow. It also shows that I am in love with pointwise mutual information, which brings us to the next point.
Pointwise mutual information and compression
The Compressors: View cognition as compression. Compressed sensing, approximate matrix factorization - The (n) Cultures of Machine Learning - HN discussion
In principle, we can compute P(a|b) for every word pair. But even with a small dictionary of 100k words (bear in mind that we need to keep all declinations, proper names and things that are not in official dictionaries, yet are in use) keeping track of all pairs would require 8 gigabytes of space.
Often instead of working with conditional probabilities, we use the pointwise mutual information (PMI), defined as:
Its direct interpretation is how much more likely we get a pair than if it were at random. The logarithm makes it easier to work with words appearing at frequencies of different orders of magnitude. We can approximate PMI as a scalar product:
where are vectors, typically of 50-300 dimensions.
At first glance, it may be strange that all words can be compressed to a space of much smaller dimensionality. But some words can be trivially interchanged (e.g. John to Peter) and there is a lot of structure in general.
The fact that this compression is lossy may give it an advantage, as it can discover patterns rather than only memorize each pair. For example, in recommendation systems for movie ratings, each rating is approximated by a scalar product of two vectors - a movie’s content and a user’s preference. This is used to predict scores for as yet unseen movies, see Matrix Factorization with TensorFlow - Katherine Bailey.
Word similarity and vector closeness
Stock Market ≈ Thermometer - Five crazy abstractions my word2vec model just did
Let us start with the simple stuff - showing word similarity in a vector space. The condition that is equivalent to
by dividing both sides by P(w) and taking their logarithms. After expressing PMI with vector products, we get
If it needs to work for every , then
Of course, in every practical case we won’t get an exact equality, just words being close to each other. Words close in this space are often synonyms (e.g. happy and delighted), antonyms (e.g. good and evil) or other easily interchangeable words (e.g. yellow and blue). In particular, most opposing ideas (e.g. religion and atheism) will have similar contexts. If you want to play with that, look at this word2sense phrase search.
What I find much more interesting is that words form a linear space. In particular, a zero vector represents a totally uncharacteristic word, occurring with every other word at the random chance level (as its scalar product with every word is zero, so is its PMI).
It is one of the reasons why for vector similarity people often use cosine distance, i.e.
That is, it puts emphasis on the direction in which a given word co-occurs with other words, rather than the strength of this effect.
Analogies and linear space
If we want to make word analogies (a is to b is as A is to B), one may argue that it can be expressed as an equality of conditional probability ratios
for every word w. Sure, it looks (and is!) a questionable assumption, but it is still the best thing we can do with conditional probability. I will not try defending this formulation - I will show its equivalent formulations.
For example, if we want to say dog is to puppy as cat is to kitten, we expect that if e.g. word nice co-occurs with both dog and cat (likely with different frequencies), then it co-occurs with puppy and kitten by the same factor. It appears it is true, with the factor of two favoring the cubs - compare pairs to words from Google Books Ngram Viewer (while n-grams look only at adjacent words, they can be some sort of approximation).
By proposing ratios for word analogies we implicitly assume that the probabilities of words can be factorized with respect to different dimensions of a word. For the discussed case it would be:
So, in particular:
How does the equality of conditional probability ratios translate to the word vectors? If we express it as mutual information (again, P(w) and logarithms) we get
which is the same as
Again, if we want it to hold for any word w, this vector difference needs to be zero.
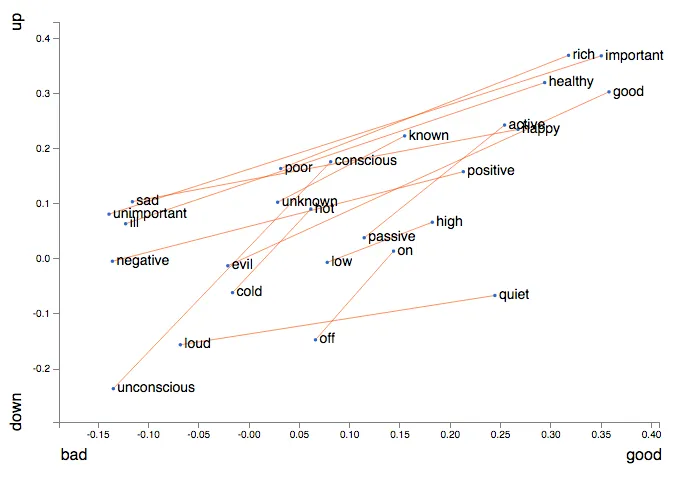
We can use analogies for meaning (e.g. changing gender with vectors), grammar (e.g. changing tenses) or other analogies (e.g. cities into their zip codes). It seems that analogies are not only a computational trick - we may actually use them to think all the time, see:
- George Lakoff, Mark Johnson, Metaphors We Live By (1980)
- and their list of conceptual metaphors in English (webarchive), in particular, look for X is Up, plotted below:
Differences and projections
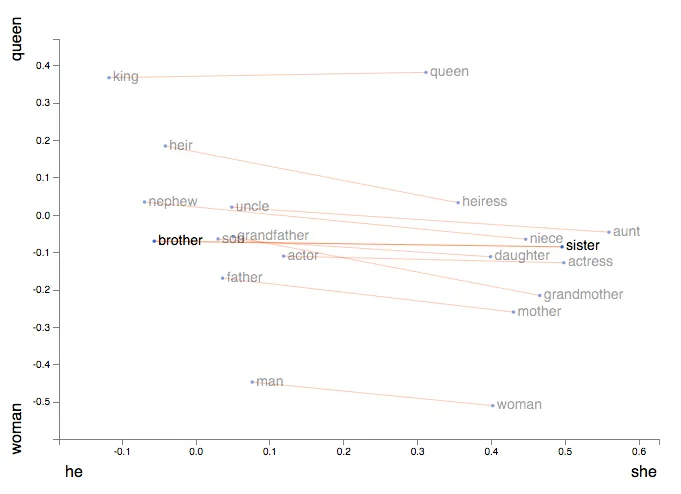
woman - man = female - male = she - he, sowo = fe = s(a joke)
Difference of words vectors, like
are not word vectors by themselves. However, it is interesting to project a word on this axis. We can see that the projection
is exactly a relative occurrence of a word within different contexts.
Bear in mind that when we want to look at common aspects of a word it is more natural to average two vectors rather than take their sum. While people use it interchangeably, it only works because cosine distance ignores the absolute vector length. So, for a gender neutral pronoun use rather than their sum.
Just looking at the word co-locations can give interesting results, look at these artistic projects - Word Spectrum and Word Associations from Visualizing Google’s Bi-Gram Data by Chris Harrison.
I want to play!
If you want to explore, there is Word2viz by Julia Bazińska. You can choose between one of several pre-defined plots, or create one from scratch (choosing words and projections). I’ve just realized that Google Research released a tool for that as well: Open sourcing the Embedding Projector: a tool for visualizing high dimensional data - Google Research blog (and the actual live demo: Embedding Projector).
If you want to use pre-trained vectors, see Stanford GloVe or Google word2vec download sections. Some examples in Jupyter Notebooks are in our playground github.com/lamyiowce/word2viz (warning: raw state, look at them at your own risk).
If you want to train it on your own dataset, use a Python library gensim: Topic modelling for humans. Often some preprocessing is needed, especially looking at Sense2vec with spaCy and Gensim by Matthew Honnibal.
If you want to create it from scratch, the most convenient way is to start with Vector Representations of Words - TensorFlow Tutorial (see also a respective Jupyter Notebook from Udacity Course).
If you want to learn how it works, I recommend the following materials:
- A Word is Worth a Thousand Vectors by Chris Moody
- Daniel Jurafsky, James H. Martin, Speech and Language Processing (2015):
- Distributional approaches to word meanings from Seminar: Representations of Meaning course at Stanford by Noah D. Goodman and Christopher Potts
- GloVe: Global Vectors for Word Representation and paper
- Jeffrey Pennington, Richard Socher, Christopher D. Manning, GloVe: Global Vectors for Word Representation (2014)
- it’s great, except for its claims for greatness, see: GloVe vs word2vec by Radim Rehurek
- On Chomsky and the Two Cultures of Statistical Learning by Peter Norvig
Julia Bazińska, at the rooftop garden of the Warsaw University Library - the building in which we worked
Technicalities
I tried to give some insight into algorithms transforming words into vectors. Every practical approach needs a bit more tweaking. Here are a few clarifications:
- word2vec is not a single task or algorithm; popular ones are:
- Skip-Gram Negative-Sampling (implicit compression of PMI),
- Skip-Gram Noise-Contrastive Training (implicit compression of conditional probability),
- GloVe (explicit compression of co-occurrences),
- while word and context are essentially the same thing (both are words), they are being probed and treated differently (to account for different word frequencies),
- there are two sets of vectors (each word has two vectors, one for word and the other - for context),
- as any practical dataset of occurrences would contain PMI for some pairs, in most cases positive pointwise mutual information (PPMI) is being used instead,
- often pre-processing is needed (e.g. to catch phrases like machine learning or to distinguish words with two separate meanings),
- linear space of meaning is a disputed concept,
- all results are a function of the data we used to feed our algorithm, not objective truth; so it is easy to get stereotypes like
doctor - man + woman = nurse.
For further reading, I recommend:
- How does word2vec work? by Omer Levy
- Omer Levy, Yoav Goldberg, Neural Word Embeddings as Implicit Matrix Factorization, NIPS 2014
- with a caveat: Skipgram isn’t Matrix Factorisation by Benjamin Wilson
- Language bias and black sheep
- Language necessarily contains human biases, and so will machines trained on language corpora by Arvind Narayanan
- Word Embeddings: Explaining their properties - on word analogies by Sanjeev Arora
- Tal Linzen, Issues in evaluating semantic spaces using word analogies, arXiv:1606.07736
- EDIT (Feb 2018): Alex Gittens, Dimitris Achlioptas, Michael W. Mahoney, Skip-Gram – Zipf + Uniform = Vector Additivity
Some backstory
I got interested in word2vec and related techniques since it combines quite a few things I appreciate
- machine learning,
- matrix factorization,
- pointwise mutual information,
- conceptual metaphors,
- simple techniques mimicking human cognition.
I had a motivation to learn more on the subject as I was tutoring Julia Bazińska during a two-week summer internship at DELab, University of Warsaw, supported by the Polish Children’s Fund. See also my blog posts:
- Helping exceptionally gifted children in Poland - on the Polish Children’s Fund
- D3.js workshop at ICM for KFnrD in Jan 2016, where it all started
Thanks
This draft benefited from feedback from Grzegorz Uriasz (what’s simple and what isn’t), Sarah Martin (readability and grammar remarks). I want to especially thank Levy Omer for pointing to weak points (and shady assumptions) of word vector arithmetics.